The Rosetta Stone, a starting point for future experts
The foundations of intelligent document assembly and automation

Written by Service Desk
Updated at October 12th, 2024
Most people, even heavy users, don’t have a handle on how to think about, how to strategize, how to visualize document automation.
Here's a one-hour non-commercial “how to” class to teach people how to figure out what they’re doing before they actually do it.
This video is one you won’t want to miss, whether you’re among the 67% thinking about moving up from cut & paste, already using our (terrific!) software, or using someone else’s tools. Whether you’re a relative novice or a world-class expert, this video will demonstrate how to grasp the structure of a document, determine the types of information required, choose the best sources for each, and determine how to most efficiently gather the information, modify it as needed, and automatically place it within a document.
The payoff for getting this right can be huge, on the order of 20% of total office costs, so this one hour of training can really make a difference to almost every professional firm and company.
| Timestamp | Subject |
| 2:28 | The Concept: Zen or "The Hitchhiker's Guide" |
| 3:07 | Sources and Sorcerer's Magic: The Form Author |
| 6:30 | The "Rosetta Stone" of Document Assembly Explains Everything |
| 25:14 | The Truly Intelligent Document |
| 26:44 | Three Very Different IQs |
| 43:28 | Document Assembly Without a Form |
| 47:07 | The Conclusion: An Intelligent Document |
C
Click on the graphic to download the "Rosetta Stone" of document automation, a playguide to who, what, when, where and why
Transcript:
Our intent is to provide all of our viewers with new knowledge. Everyone from those who recognize the term document automation but aren't certain what it means to the real rocket scientists with years of experience.
We hope to explain in less than an hour how best to determine whether automating a document makes sense, how to analyze documents to determine their components, and how to structure the automation process.
These insights will save you time and trouble on every single document you create, modify, or make intelligent.
This presentation will not be a commercial for our own software.
We'll barely even mention its names.
Instead, we'll work to use broad principles that you'll benefit no matter what tools you use or even if you're part of the sixty eight percent who still manually build every document no matter how repetitive.
Scott Campbell has been creating documents professionally for nearly three decades and has more than a million pages notched into his keyboard.
He's a master, a guru, a word warrior always looking for a better way, thinking up new ideas to make the process more efficient, eliminate errors, and reduce the stresses incumbent with last minute changes.
I think you'll find what he has to say interesting and most valuable.
Here's Scott.
Thank you for joining us. Yes. These are gonna be theories, general principles, concepts applicable to everyone.
If you heard someone mention the term document assembly before and thought, well, maybe that could be useful, This will give you a really solid background on exactly what it can do. And if you're already the expert document assembly person in your office, this will give you some analytical tools that'll clarify your thinking so that when you approach a document, you approach it from a distance with a bird's eye view instead of being stuck in the middle of the forest bumping into trees.
What is document assembly?
It is the process of taking a whole bunch of words from a whole bunch of different sources and combining them all into a single letter perfect finished document.
If it's done correctly, you end up with no errors, minimal proofing requirements, perhaps no proofing requirements, and breathtaking speed.
A really good automated document feels like magic to the end user.
We're talking today about the task of the form author.
The form author has to get from the document on the left to the document on the right.
Here we have lots of blanks to be filled in, a whole area here that's, needs to be drafted, signature block at the bottom.
We need to wind up when we're finished with this perfect document, no errors, all the way from beginning to end.
Let's look at where all this information is gonna come from.
I've got four different sources of information here, four different places where words come from to ultimately land in the finished document.
The first one here I've coded it with, black is the body of the form.
Over here in the form on the right, I've got this text in the heading, the title of my pleading, a standard paragraph here that's gonna appear in every finished document, some more headings, and so on.
So not a lot of the material in the finished document was actually typed into the body of the form, but it provides the framework for the whole thing. You can think of that as a framework.
Next up is the questionnaire.
Every document assembly software has some form of a questionnaire.
For those of you using the form tool in Docsara, we call it the q and a table and the grids.
But there's gonna be some paradigm for asking the form user a series of questions and then using those responses to fill in the finished document.
Over here in this document, that would be the blue and green areas.
The name of the plaintiff, the name of the defendant are coming from the questionnaire.
And here, I've got a list of shareholders and the shares each one owns as part of the questionnaire.
Other information comes from external sources. First, external documents.
In this document, I've got case authority, which has been pulled in from an external document outside the form, goes on for a while here.
And external data sources, in this particular form, I've got up here in red the name of the judge, the courtroom number, the county, all coming from an external data source, and the names of the signing attorneys along with their bar association numbers and email addresses coming from an external data source, which is great because it means the form user doesn't have to know how to spell any of those names. They can just pick them from a list, and they don't have to know the corresponding information that goes along with each one of those names.
So now let's look at the form author's job of parceling out all these various bits of information into all these various locations.
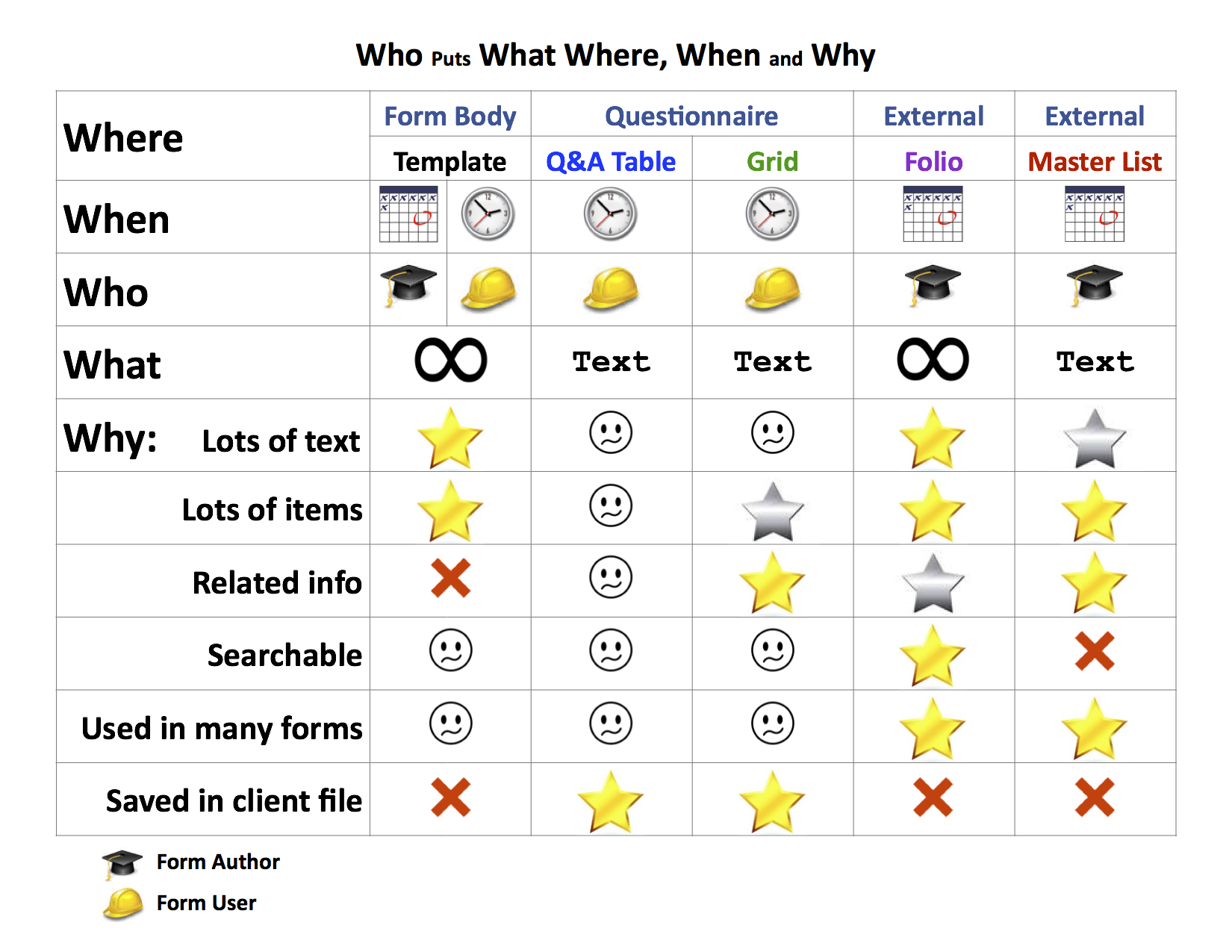
It can be a little overwhelming. This is the great big who puts what, where, when, and why chart.
I'm gonna shrink this up, so we can see the whole thing at once.
And this can understandably be overwhelming.
So we're gonna go through it slowly. I'm gonna pull across the curtain here, so that we can focus on one thing at a time.
First off, the where.
These are the four different sources we just talked about, where information comes from.
Generic terms on the top. If you happen to be using our product, this is how we use how we refer to each of them within our product. But every product is gonna have its own terms for those places.
And the next row here is when and who.
Now we'll get into the meat of it.
Most of the content of the, form body is created by the form author. I've got a little scholars hat here indicating the form author, and it's created well in advance of when the form is used.
Days, weeks, or months in advance.
That makes up the bulk of the form body. But keep in mind that the form user, after they create the document, at the time that they use the form, could also go into the finished document and type in their own information there too.
Just manually type it in without the assistance of any document assembly product. They too have access to the body of the form.
The questionnaire is the exclusive province of the form user.
They're the ones who answer those questions. The form author created the questions, but the questions themselves are not gonna be used in the finished document. It's the responses to those questions that are provided by the form user that are gonna be incorporated in the finished document and that are gonna drive the decisions that are made to produce the finished document.
The external information, either external documents or external data, are all created by the form author well ahead of time.
The next row here talks about what.
What is it we're talking about? What information is being stored in each of these places?
In the body of the form, it could be absolutely anything. It could be headers, footers, footnotes, end notes, graphics, hyperlinks, tables, charts, formatting, styles, absolutely anything that you can type into a Word document, you can put into the body of a form.
In the questionnaire, as the form user is responding to those questions, you're limited to text.
The form user cannot determine formatting, add footnotes, hyperlinks, images.
All they can do is provide text responses to your questions.
In the external documents, once again, you can include anything at all. Anything you can put in the body of the form, you could also put into an external document and then have it pulled into the form from the external source.
And in your external data sources, again, you're generally going to be limited to just text.
You can't put graphics and so forth in your external data sources.
Just using these first three rows, we can already make lots and lots of really good decisions about what information belongs where.
For example, if it's information that is only known by the form user at the time that the form is filled in, then it's got to go in the questionnaire or you have to expect the form user to manually type it into the document themselves with no assistance from document automation.
If it's information that is known well ahead of time, then it should be provided by the form author. Don't make the form user type anything that you know in advance.
If it is formatted information with graphics and hyperlinks and so forth, you're gonna have to put it either in the body of the form or in an external document from when it will be inserted into the the finished document.
And if it's text, then you're free to have that in the questionnaire or in an external data source.
Now we move on to the why. This is where it gets exciting.
We have many different considerations involved in why.
Here they are.
And the key to this is you're looking for gold stars. The gold stars are the best places to put information.
The silver stars are still very good.
The little meh faces mean, yeah, you could put it there, but really why would you want to? It's kinda lousy.
And the red x's mean it's impossible. You just can't put that information in that repository.
Let's hide these lower ones again.
And the first consideration we'll talk about is lots of text.
If we're talking about lots and lots of text, multiple paragraphs, multiple pages, maybe even whole chapters of a document, then you wanna put that either in the body of the form or in an external document where you can insert it into the finished document as needed.
External data sources are also sometimes a good place for lots of text. Imagine, for instance, maybe you've got a dictionary of words with a definition for each word. Those definitions might run on and on and on. They might get quite lengthy, but they're all text with no images or, any other special formatting required. So you could actually put those in an external data data source instead of an external document. It would be a little more efficient that way.
The next consideration is, are there lots of items?
If it's agreement that has hundreds of paragraphs in it, that's a lot of items, and you can just put those right into the body of the form. That's a great place for them.
If it's a list of shareholders, maybe there are ten, twenty, thirty, a hundred shareholders, the form author doesn't know the names of the shareholders in advance, so they can't be typed directly into the body of the form, but they can be put in the questionnaire.
And I've separated this questionnaire into two columns just for our form tool users, because for them, the grid is an excellent place to put a lot of items. The q and a table, not so much. So make sure to take advantage of the grid when you can. And for other software, be familiar with the different structures of the questionnaire so that you can really leverage them to put lots of items in a place where it's gonna be easy for people to enter that information.
In an external document, so suppose you had a you work in a law firm and you've got a hundred attorneys in the firm. That's a lot of items, and you want to store their biographies along with a photo of each attorney to be used in publicity materials.
You'd put that in an external document because it's great at handling lots of items, and it's also capable of handling the photographs.
In the external data source, maybe you've got a list of all the IRS offices in the United States along with their, addresses and phone numbers.
That's all straight plain data. There's lots of items. And external data source would be a great place to put that.
The next consideration here is related information.
By related information, I mean two pieces of data that need to be linked together.
In the body of the form itself, if you put someone's name up near the top of the document and their email address down near the bottom of the document, there's really nothing tying those two pieces of information together, nothing that the program can make use of. It has no idea that the name at the top is related to the email address down at the bottom.
So you cannot do related information in the form body.
In the questionnaire, again, if the structures that your software program has for, its questionnaire in the form tool, the grid is an excellent place for related information.
The q and a table, not so much.
External documents can be a very good place for related information. Imagine if you had an external document which is a collection of case authority and you've tagged each case with the qualities of that case. This is a bankruptcy case that involves a value over a million dollars.
This is a property dispute case that involved personal injury as people were punching each other over the fence line.
You can categorize all of those cases in your external documents so that you form relationships among them.
Then later on, when you need to, put some case authority in the document you're creating, you can look for all of the the authority that relates to the particular type of case you're dealing with. So those are important relationships that can be maintained in an external document.
External data sources are just spot on tailor made for related information.
You might have a, a listing of all the judges in your jurisdiction along with each judge's courtroom number, the name of their clerk, the clerk's phone number, the address of the courthouse, the county in which they operate in, all this related information tied to each judge's name so that it's immediately accessible to everyone in your office.
The next consideration here is doesn't need to be searchable.
You could search for text in the body of a form and in the questionnaire, but not very well.
You can't easily search for a particular word or phrase that appears across multiple forms, for example.
Searching for a word or phrase in the questionnaire is not gonna be a terribly productive activity usually.
External data sources are generally not easily searchable.
You may get lucky lucky and get a product that does a better job of that than others.
But external documents, and I'll show you an example of this in a few minutes here, can be fantastically searchable and can be leveraged in really extraordinary ways. We'll see that in a minute.
The next one up here is, is this information used in lots of forms?
Think of an acknowledgment block that appears in dozens or hundreds of forms in your office.
It's formatted the same way every time.
It has the same language.
It appears all over the place.
You could type that acknowledgement block into every single one of those forms, But don't!
That's a terrible, terrible process.
Don't type information that appears in multiple forms into every one of those forms. You're duplicating effort, causing yourself work.
Also, I could ask the form user to type their desired acknowledgement directly into the questionnaire, but don't. That would be a terrible thing to ask someone to do.
So anytime information appears in multiple forms, put it in an external source, either a document or a data source.
I can put that acknowledgment into my external document, including all of the appropriate formatting, any underlining that I need, any tab settings, any margin settings, put that all in my external document, and then sometime somewhere down the road, if someone in the office has a great idea about how the language in the acknowledgment block ought to be changed or updated, you can make that change in one place in your external document, and then every single one of your dozens of forms is going to pull in that revised language into the individual form when form is used.
Imagine, in an external data source, you might have a listing of all the people in your office along with their email address, their direct dial number, And then in every single one of your forms that requires a signature from one of those people, the form user can just select a person from a list and all of the accompanying information can come along with it automatically.
And finally, does the information get saved in the client file?
Every document assembly software is going to have the capability to take all of the answers in a questionnaire after the form user has filled in a particular form and save those responses somewhere other than in the form itself.
So that the next day, when that form user goes to create another document for the same client or the same matter, they won't have to type in a lot of information that they typed yesterday. They can just load in the answers that they saved yesterday.
And, yeah, this form might ask for some additional information, but there's gonna be a lot of overlapping information. So they get a huge head start on the second form because all of the basic information is already provided.
On the second day, they'll type in some more information because they have other questions to answer.
And then they'll save those additional answers into the answer file. And so over the span of time, all of those answers will accumulate. And a couple weeks into the case, you'll find that you're creating entire finished documents without having to type a single word.
So does the information get saved in the client file? If it does, you've gotta put it in the questionnaire.
That's the information that's going to get saved out of one form and then loaded into another form to give a big head start.
And just think of worrying about how to spell a person's name once the very first time that you write it down.
Once you've done it correctly that first time, it's gonna be correct forever.
You never have to worry about it again because that first round of information gets saved, It gets reviewed and corrected if necessary, and then it's correct forever after.
So if you happen to use our product, you can just take a screenshot right now, and you've got this chart.
If you use another product, I would recommend that you take a close look at it and think about it in these terms, and maybe even draw up a chart for yourself if you find that useful. But at least kind of apply the thought process that I've used here to your own individual product product, so that you're aware of where these gold stars are.
You really want to leverage these gold stars.
Any particular piece of information has a really good place to go, and all you need to do is analyze it, and, you'll be able to get everything parceled out correctly.
Okay.
So that's the who puts, what, where, when, and why.
Now we're gonna move on to smarts.
You remember at the beginning, I said that document assembly is the process of taking a bunch of different words from a bunch of different sources and combining them all together into a finished document.
Well, if we just took all those words from all those sources and piled them into a document, what we would wind up with is something like this, highly undesirable.
So instead, what we're really doing is we're taking all this information from all these different sources, and we're applying an intelligence to it. We're thinking about it.
When we create the form, we're teaching the form how to think about it. We're transferring our intelligence into the automated form.
The thinking process looks at all the available information, most importantly, the stuff that comes from the questionnaire.
It's deciding which information applies, which does not. It's sifting through it, picking out certain bits and pieces, and then taking all of that and beaming those words into the document with pinpoint laser like accuracy into exactly the spots where they're needed.
No errors. Ever.
And so let's look at that intelligence.
I'm gonna show you three, examples of intelligence applied in a single, form here.
First, we have some basic intelligence.
I need to show you the questionnaire that corresponds to this form. It's down here at the bottom.
This questionnaire asks for the name of a signer, the name of their spouse, their location of their residence, the name of their employer, a list of their children's names, and the birth date for each one of those children. A lot of basic information.
Given that information from the questionnaire, the, automated document when executed, I'll do that now, takes the information from down below and pops it into the form up at the top. My name is John Doe. I reside in Alabama, etcetera, etcetera. It's taking these words that appear in the questionnaire and popping in them into the appropriate location in the document.
Here it's taking one piece of information and using it twice. That's great. We have not only put the information where it belongs, but we've also saved the typist some time because we've put it in twice and they only had to type it once.
This is basically just a Word merge.
You can accomplish this with the merge capabilities built right into Word.
And if you do that, if you create forms either with Word or with a a document assembly product, and all you're doing is is popping the fields into their locations up here in the document, I applaud you. That is fantastic.
You took five or ten minutes to learn how to do this.
You took a weekend and you took your ten most recent most frequently used forms and you applied this simple automation to them and you are immediately saving yourself hours and hours every single week. This is great.
If you wanna go further than this, we'll show you how it can get a little more sophisticated.
Notice in this document that we have the company name, Acme Inc, period, followed by the period that ends the sentence.
Well, that's not great. We would wanna clean that up and get rid of the second period.
Also, here, we're referring to a Alabama resident rather than an Alabama resident. That's not optimal.
And the language here is a little awkward. My spouse is also a Alabama resident, and my spouse's application is attached here too.
It's okay. We can get by. Here it also says my spouse's name is Mary Marydell.
And here in the list of children, the form author allowed for a maximum of four children. We only used three spots, so we'd need to come back here and clean this up a little bit too. If we had five children, we might have to tack another one on there manually.
So let's move one step beyond this.
Here I have a medium form. I'm gonna reset this.
And at some point, the document assembly artist realizes something very important.
You're not limited to the words that the form user typed into the questionnaire.
You can just refer to those responses and make use of them to drive your own language, to drive language that is created by the form author. For example, this paragraph is gonna either say I am married or I am not married depending on whether or not a name appears in this field, the name of spouse.
This paragraph is gonna either say, I live in or outside the United States depending on whether or not this response is a state or territory of the United States.
This paragraph is gonna do an amazing amount of stuff. It's gonna count up the number of children, tell us how many there are, then it's gonna look at all the dates, all the birth dates here, and calculate each child's age.
It's again using that age, it's then gonna determine whether or not each child is an adult or a minor.
And given that information, it's gonna determine the mix of adults and minors in the group of children so that it will end up either saying they are all adults, they are all minors, or they are both minors and adults.
I'm gonna click the button to fill this in so we can see the results.
And our three paragraphs there say, I am married. I live in the United States.
I have three children. They are both minors and adults.
Watch what happens when I come down here and remove the spouse's name.
Change the, location of residence to Florence, Italy.
And let's say that Anne Doe was born in two thousand three.
Now I fill it in again.
And I get, I am not married. I live outside the United States.
I have three children. They are all minors.
So this is enormously liberating to the form author when they sort of get over this hurdle, this speed bump, and they realize I can say anything I want.
I can look at what's written in the questionnaire, what the forum user responded, and then I can think about it, and I can make some decisions, and I can put in whatever language I want.
Let me reset this.
And now let's look at an extreme case.
Here's an advanced form, and this is just comical.
I have stacked the deck here. You will never ever in your life create a form that is as densely coded as these two paragraphs. There's more code here than there is text.
So don't be alarmed and think that this is what forms are gonna look like once you get into the document assembly world. This is this is a stacked deck.
But let's look at the result the end result when I click the fill button here.
And let's read it. My name is John Doe. I am a US citizen currently residing in Florence, Italy, and I am employed by Acme Inc. I am not married. I have three children who share my residence, all of whom are minors. My daughter, Rando, age eleven, born April seventeenth two thousand three. My son, Joe Doe, age thirteen, etcetera, etcetera, etcetera, it lists the children.
You notice how conversational that sounds?
It's not awkward at all. It's not like this one up here at the top.
And it looks great.
It looks like it was handcrafted and then typed by an expert stenographer who makes no typos whatsoever.
It's it's it's perfect.
And it's very, very smart. I counted it up.
I tallied up the various ways, distinct ways in which this little form is smart, and I came up with fourteen ways.
Let's look at them.
Number one, it eliminated that annoying double period after the employer name here. Here it says Acme Inc. Period, and it was smart enough to remove the extra period that, would otherwise have appeared at the end of that sentence.
Number two, it determined whether or not I'm a US resident.
Here it says, I am a US citizen currently residing in Florence, Italy. But if we had chosen Alabama here as the residence before we filled it in, it would say, I reside in the state of Alabama.
No mention of US residency.
It also is describing the location.
Here it says the state of Alabama expanding upon the word Alabama that was selected down here.
But if I chose American Samoa and filled it in, It would say, I reside in American Samoa, a US territory.
Fantastic.
Number four, gender words. Let's put the name of the wife back in here, Jane Doe.
That's a she, and fill it in.
And look at all the gender words that are handled automatically.
My wife's name is Jane Doe.
She is also an American Samoa resident, and her application is attached here too.
Also, down here, I've identified all the daughters and sons amongst the children.
That's gender words.
A and. Remember up above where it said, a, Alabama resident? I think it said we're going to American Samoa here, which is which is just as good. Because down here, it says she is an American Samoa resident instead of up here where it says she is a American Samoa resident.
It's counting the number of children, and then it's taking that number, that numeral, and converting it into word format.
So I can say I have three children.
Imagine a purchase and sale agreement where the value of the transaction is ten million five hundred eighty six thousand four hundred and seventy three dollars and seventeen cents.
You can just type that number in the answer box in the questionnaire, and then up in the body of the form, it can expand that number into words for you.
No errors. Always consistently formatted.
All that conversion done for you automatically.
Number eight, it's converting date formats. Down here, I typed four seventeen two thousand three, and up here it says April seventeenth two thousand three.
Number nine, it's listing children narratively with proper punctuation. This is a hugely important one.
This form will accommodate any number of children from zero to, whatever number you wanna come up with.
And it's gonna take, though, that listing, and it's gonna recite them in a narrative format with proper punctuation.
So it's here's the first child, my daughter, Anne, semicolon, the second child, semicolon, the word and before the last child, and then finish up with a period. It'll reformulate that listing depending on how many children there are.
It's calculating ages based on birth date. It's taking this date here and comparing it to the current date and coming up with an age for that child.
Having determined the ages, it's then comparing that number to eighteen to determine whether each child is an adult or not.
And having done that, it's determining the mix of adults versus minors amongst the children.
So that it can say something like this, all of whom are minors.
If I crank up Anne's age again, let's make her an adult, then this whole sentence here is gonna change dramatically. It's not gonna say minor is here anymore. Watch what happens.
I have three children, my adult daughter, Ando, my son, Joe, a minor, and my daughter, Faye, a minor.
Number thirteen, singular plural words like child, children. And number fourteen verb forms.
Here it says, I have three children who share my residence.
But, if I took it down to one child, it would say, I have one child, child instead of children, who shares my residence. The verb form matches the singular or plural form of the noun.
So it's doing tons and tons and stuff. And and the great irony here, which I just love, is that the more intensely and expertly automated a form is, the more roboticized a form is, the more it ends up sounding like it was handcrafted by a human being.
Remember how these two sentences sounded up here? My spouse's name is Jane Doe. My spouse is also a American Samoa resident, and my spouse's application is attached here too. Compare that to my wife's name is Jane Doe. She is also an American Samoa resident, and her application is attached here too. It just sounds great.
So that's what you're shooting for if you really wanna get deeply, deeply into this. If you don't, that's fine. More power to you. You can save tremendous amounts of time with the most basic sort of document assembly.
And then, if you get into it, if you have an aptitude for it, if you enjoy it, go further. You'll discover you can say anything in the form based on what's provided in the questionnaire.
Okay. Finally, in our last few minutes here, I'm gonna run through a couple of real life scenarios.
I can't give you a demonstration of this using every document assembly software, so you'll forgive me if I use the one I'm most familiar with.
And let me expand my menus.
So I'm gonna show you two, two applications of document assembly. And the first one might surprise you because it doesn't even use a form. This may be an application of document assembly that it never occurred to you that you might use.
Let's suppose I'm an attorney working in a law firm, and I have hand drafted this, motion to notify shareholders.
I just typed it from scratch.
Maybe I used a template to get my pleading format to start with, but then I just started typing in here. And right here, so no forms used at all. So right here where my cursor is flashing, I want to insert some case authority.
And I know that my office has a fantastic new document assembly software that lets me fetch information from a library of of, information and insert it into my document where needed. So I'm gonna fetch from my authority folio. That's an external document.
And that authority folio, just contains a whole lot of case authority here. Each one of these items is a separate case with some discussion of each of them.
And I wanna find ones that are applicable to the case I'm working on. So rather than laboriously go through here one at a time and look at them all, I'm gonna filter these results, and I only wanna look at the ones related to personal injury. I have several choices here, bankruptcy, hostile takeover, etcetera. I'm clicking the personal injury checkbox, and now I've got a much shorter list of possibilities. There's just four cases in here that relate to personal injury.
Well, I know my case is all about rubber baby buggy bumpers, so I'm gonna type the word rubber here and do a search.
Now I've only got two cases to look at.
And over here on the right, it's showing me the content of the first one, and it has highlighted the word rubber for me here. So I can see he claimed that rubber baby buggy bumpers were a significant contributing factor. Oh, that's interesting. That's something I might want to cite in my pleading.
Let's look at the second one here.
Here's the word rubber highlighted. It says plaintiff asked that his rubber baby buggy bumpers be restored to their original condition.
Well, that's good too. I'd like to include both of these cases in my pleading. So I click both the check marks.
I fetch them into my document.
Remember and I've color coded this just for demonstration purposes so you can see what was inserted.
And here I've got, great, a nice description of this case, a nicely formatted indented quote from the case.
Here's the second case with similar information and a couple of footnotes here to cite those two pieces of authority.
That's just fantastic.
So it's a library of information that is searchable. Remember we talked about searchable when we were looking in that big chart?
Searchable by all sorts of different criteria, and easily inserted into documents when and where I need them, even if I'm not using a form, even if I'm drafting from scratch.
Now the last thing I have here is, more of what you would expect from document assembly.
This is the form that we started out with. Remember, we had all the color coded items that are being filled in from various different sources, and we're gonna actually run this form now. Here's the questionnaire, and I've cheated. Rather than fill in all of these answers from scratch, I'm just gonna load in some answers that I saved previously.
Here they are.
So whoever answered these questions, they were asked what type of case is this, and they were given several, choices, bankruptcy, corporate malfeasance, hostile takeover, personal injury, property boundary dispute, they chose corporate malfeasance.
Then they filled in the name of the plaintiff, the name of the defendant, the cause number. They were asked for a presiding judge, and they chose that judge from a list of possibilities.
And then they were asked to provide the names of a couple signing attorneys, and those also they chose from a list of possible signing attorneys.
Then they filled in the names of a bunch of shareholders along with the number of shares each one's holds and the offices held by those shareholders, if any.
After filling in all of that information, they click the magic button to fill in the form, and they end up with a finished document.
And let's look at the sources for this information.
Red, remember, is an external data source.
So the program went out to an external data source to pull in the full formal name of that judge, and it grabbed his courtroom number.
It also grabbed the county that he operates in, King County.
This blue information came from the questionnaire, the name of the plaintiff, the name of the defendant.
This green information also came from the questionnaire. It came from the grid.
And the first chart here is pretty much just a straight transcription of what was entered here.
But the second green chart pulls draws its information from the exact same source, but it arranges it completely differently, and it filters it. It's giving us a subset of that information.
It's listing only the officers and the name that corresponds with each office.
Same set of information, two different outcomes in the same document.
And the authority is all this purple stuff. Let's look. We've got we've got about three pages of authority that all came from an external document, a folio.
And how did it determine what cases to use?
That was all driven by this very first question in the questionnaire.
It asked, what type of case is this?
And the form user chose corporate malfeasance.
So the program went out to our external source of case authority, and it found all the cases that relate to corporate malfeasance and popped them all in here.
I can edit these now. I don't have to go with exactly what was provided, but what a huge head start I've got. I've got five different cases that probably apply to my case as a starting point, and I can edit them as needed.
Down here at the end, we have, again, some red text. So that came from an external data source.
It pulled in not just the name of each signing attorney, but also that attorney's bar number and email address.
And that wraps up our show for today.